

Implementing SAP, or any major ERP technology, can be a daunting endeavor. But getting your data into SAP and validating that the data loads are correct doesn’t have to be.
With the right approach, processes and tools, you can manage data quality and reduce the risk of data inaccuracy or loss. Data inaccuracies may sound minor, but they can actually cause business processes to falter or fail after go-live, so it is important to prioritize a validation process to ensure a successful conversion. This step-by-step guide is useful for SAP R/3 and SAP S/4HANA data migration for utilities. Based on many years of experience with utility clients, these are the processes I recommend for a successful SAP data conversion. Get ready to get geeky!
Approach
The typical tools for an SAP data conversion project are SAP BusinessObjects Data Services (BODS), the Legacy System Migration Workbench (LSMW), and a file storage system (ftp in the diagram below) along with a relational database management system (RDBMS).
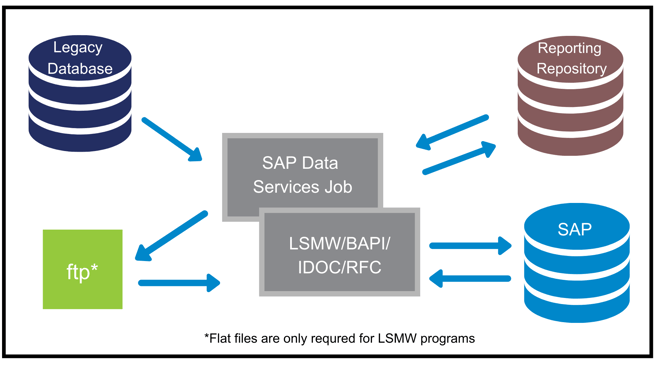
The diagram above visually represents the flow of the data in the SAP migration steps listed below. This is an iterative process, and each load would go through all these steps before the next object load starts. A simplified example would be five load programs for operational data: one for work center, two for functional location, and two for equipment. In this case, you would iterate through the 5-step process below five times.
Load Process
- Extract and transform data from the legacy database.
- Prepare the legacy data and create flat files if using LSMW, or store in a reporting database for staging and audit purposes.
- Validate the staged data and create reports to audit counts and expected fallout.
- Iterate the first three steps to manipulate legacy data so that it loads into SAP without issue. Mock loads will allow you to test and validate loads to iterate the legacy transformation.
- Use Data Services to call LSMW programs to read flat files to load into SAP, or call a BAPI, or load an IDOC. If you use BAPI or IDOC for loading, then you don’t need to save the data in a flat file.
- Execute post load validation jobs in Data Services to compare data in SAP with staged data to find unexpected differences.
With the power of modern compute, you can easily validate millions of records of data. Rather than spot checking or relying on counts alone, Data Services can compare all data loaded into SAP and show exactly where the discrepancies are.
Blueprint
During the blueprint for an SAP data migration, you’ll want to create the following artifacts, or ensure they are carried over from project preparation:
- Communication Plan/RACI Matrix (Prep)
- WBS/Project Schedule
- Template Mock Schedule (Prep)
- Mock Data Load Goals/Objectives
- Technical Architecture
- Data Flow – to include data dependency requirements
- Functional Specifications
- Data Mapping Documentation
- Data Dictionary
It’s important to have these documents in place prior to starting the realization phase. These documents will help manage expectations, control scope, and keep the project on track for success. During the data mapping exercises, it’s best to have your subject matter experts come together with an experienced SAP implementation partner. This ensures that there are no missing data points and common issues are sorted through prior to running into them during realization.
Having a trusted SAP implementation partner walk you through the blueprint will greatly reduce risks for migration and cutover.
Utility Operations Data
The core objects of the operations data for utilities are work centers, functional location, equipment, maintenance plans and work orders. Each of these load objects will have additional details and may have multiple loads. For example, equipment will have class and characteristic data that will need to be loaded after the initial equipment creation load. The order of load is also important. You must load work centers before you can load functional locations, and functional locations should be loaded prior to equipment. The data flow mapped out in the blueprint phase will help define these dependencies and identify preload validation.
Load Process Defined
The load process consists of five steps that are iterated as many times as needed for each load object. Each load should have its own set of Data Services jobs and load programs to process and move the data.
Remember that consistency is key, so try and design a set of jobs that follow a set of standards to keep risk low.
Simplified steps and data flows in Data Services will make it easier to rerun jobs as needed or pick up processes in the middle rather than having to run a single massive ETL process from beginning to end each time.

Data Validation
This step is where the rules come into play. You might add rules for foreign key constraints, datatype checks, or expected values. SAP text tables play a key role in many rules. Below is an example of the high-level flow of the Data Services job for functional location preload validation. The first node is a script that sets the variables. The second node is the workflow that loads all the needed text tables into the reporting repository database. The third node is a validation dataflow. And the last node is the update to the audit table.
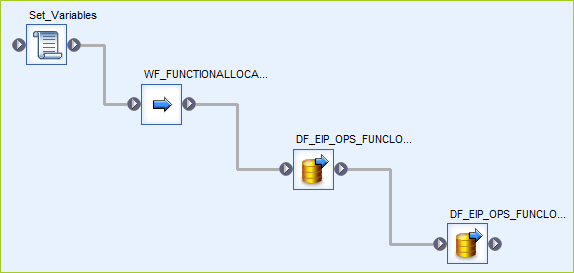
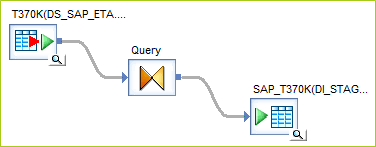
The workflow to load the text tables is a very simple process. It is a straight extract of text tables from SAP into the reporting repository. This is for two purposes. First, it allows for easy validation in a validation transform in the next node. Second, it creates a snapshot of the text table to ensure what you are comparing against is what you expect to see in the data values. Below is an example of the T370K extract. This is used to check and make sure EQART, type of technical object, aligns with what’s expected in SAP.
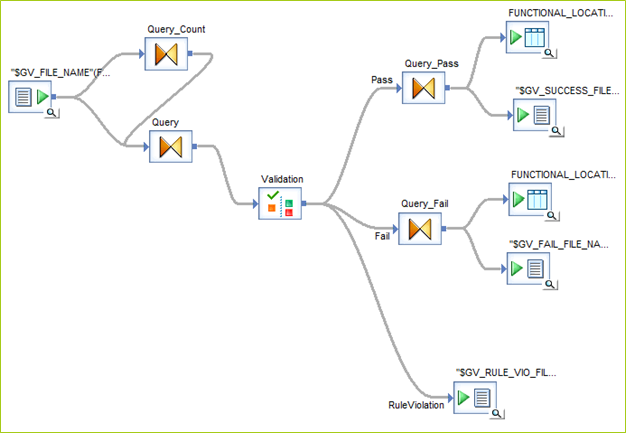
The validation dataflow is shown below. The staged data is in a flat file represented on the left side of this screenshot. It is processed through two query transformations. One simply checks for duplicates by primary key. The other maps the data for the validation transform. Records pass through the validation transform and either pass or fail the rules set in that transform. Pass records go to the Query_Pass transform while fail records go to the Query_Fail transform. The output is captured in a temporary database table in the reporting repository and a flat file for each set.
Validation rules example:
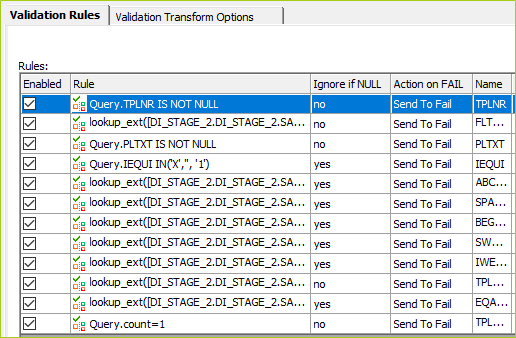
This is set inside the validation transform and changes depending on the load requirements for your project. As you go through mock loads, reasons for load failures should help create new rules for preload validation. The purpose of preload validation is to prevent load failures in the first place. So, modify as you learn of exceptions.
Post-Load Validation
For post-load validation, the process sets variables, extracts from SAP and stages the extract in the reporting repository, compares preload data with SAP extracted data, creates match/mismatch flags for each data field, and updates the counts in the audit table.
There are many ways to compare the data between preload and SAP, but the simplest way is using a query transform with decode statements. This is a more tedious build but allows for additional control of the comparison. You can do things like set nulls to blank spaces (a default when extracting through RFC table connections in SAP). You can also map values like language = ‘EN’ and language = ’E’ as equivalents. This is important for differences in values and unconverted values. Many of the differences are nuances that don’t impact business needs – like left padding certain values with zeroes. Below you can see I added a null value conversion to single space for match comparison.

The goal is to validate that the data was loaded accurately and as necessary to meet business needs. If the data is useable by the business users and equally represents what is expected, even if slightly different, then it should pass validation. Take the time to go through and look at side-by-side examples. Go through and look at mismatches. Are the mismatches detrimental to the business, or explainable to a degree that still has similar meaning carried over from the legacy system?
Best Practices
- What tool should be used for SAP migration? SAP Data Services is the standard and has the best integration with SAP. However, many ETL tools are available to do the job. Be sure to look at what ETL tools you already have, and whether or not it makes sense to implement Data Services if it is new to your organization. When adopting new technology, such as Data Services, consider engaging a Subject Matter Expert at a consulting firm that specializes in utilities. Firms like Utegration can help make sure you get the intended benefits, and achieve value from your investment faster.
- For each database connection, use a single datastore in Data Services and configure it for each environment tier in the landscape.
- Create a Data Services job for each step in the process. Number the jobs to easily identify run order. Standardize job names so they show up in order.

- Create scripts and variables for tracking purposes. I like to create instance numbers based on a database sequence to track the load process from start to finish. There’s an audit table in the reporting database that stores the table counts for each instance and any file names used for loading.
-
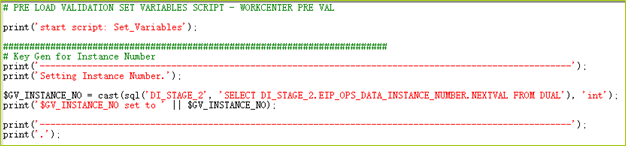
- Here’s the beginning snippet of code from the preload validation job for work centers. You can see where I set $GV_INSTANCE_NO based on a SQL function call to the DI_STAGE_2 database. In this scenario, the business transformed the data and packaged it into the reporting repository tables that I picked up and validated for load. So, I started with the preload validation step while another team took care of the first two steps in the process. The segregation of duties for this project had the business analysts performing the extracts and audits to provide data for loading purposes.
- The audit table typically has the following fields. The first entry in all caps in the list below is the technical name from the example screenshot. It is followed by the business description of the field.
-
- INSTANCE_NO - Instance number
- LOB - Line of business/division/commodity (however the loads need to be split up)
- LOAD_OBJECT - Load object
- INPUT_FILE - Legacy count
- DATA_CONVERSION_ERRORS - Data conversion error count
- RULE_VIOLATIONS - Preload validation rule violation count
- READ_TO_LOAD - Preload validation pass count
- SAP_MISMATCH - Post load mismatch count
- SAP_MATCH - Post load match count
- N/A - Extract and stage run timestamp
- PRE_VAL_EXECUTION_TS - Preload validation run timestamp
- POST_VAL_EXECUTION_TS - Post load validation run timestamp
- N/A - Relevant file names (could be multiple fields depending on the circumstances of the project)

-
- Here’s the beginning snippet of code from the preload validation job for work centers. You can see where I set $GV_INSTANCE_NO based on a SQL function call to the DI_STAGE_2 database. In this scenario, the business transformed the data and packaged it into the reporting repository tables that I picked up and validated for load. So, I started with the preload validation step while another team took care of the first two steps in the process. The segregation of duties for this project had the business analysts performing the extracts and audits to provide data for loading purposes.
-
- Manually save off data as needed to archive and save for audit purposes. List out the steps of each run of the process and follow the checklist as you go through the process in each mock load.
Wrap-up
For a successful SAP data migration, preparation is key to reducing risk and managing expectations. I hope this blog provided helpful insights and that you gained a clear overview of the SAP data migration process. If you have any questions, or need a data advisor, our data and analytics group can help. We have a lot of experience with multiple data migration projects and would be happy to help advise as experts in SAP for Utilities. Contact us here to discuss your data questions.